Splitting multi-period into single period load files


When loading data into Oracle EPM applications the tool of choice is Financial Data Quality Management Enterprise Edition (FDMEE). Dating back to Classic FDM it has been possible to load either by single period or multi-period.
In Classic FDM there was a performance penalty associated with processing multi-period files. The issue with Classic FDM was that behind the scenes the application would split a multi-period file into single period files. This added extra overhead into the process and depending on the size of the files could lead to significantly slower processing. This is probably due to the underlying technology being a mix of Java, .NET and Classic Visual Basic (VB).
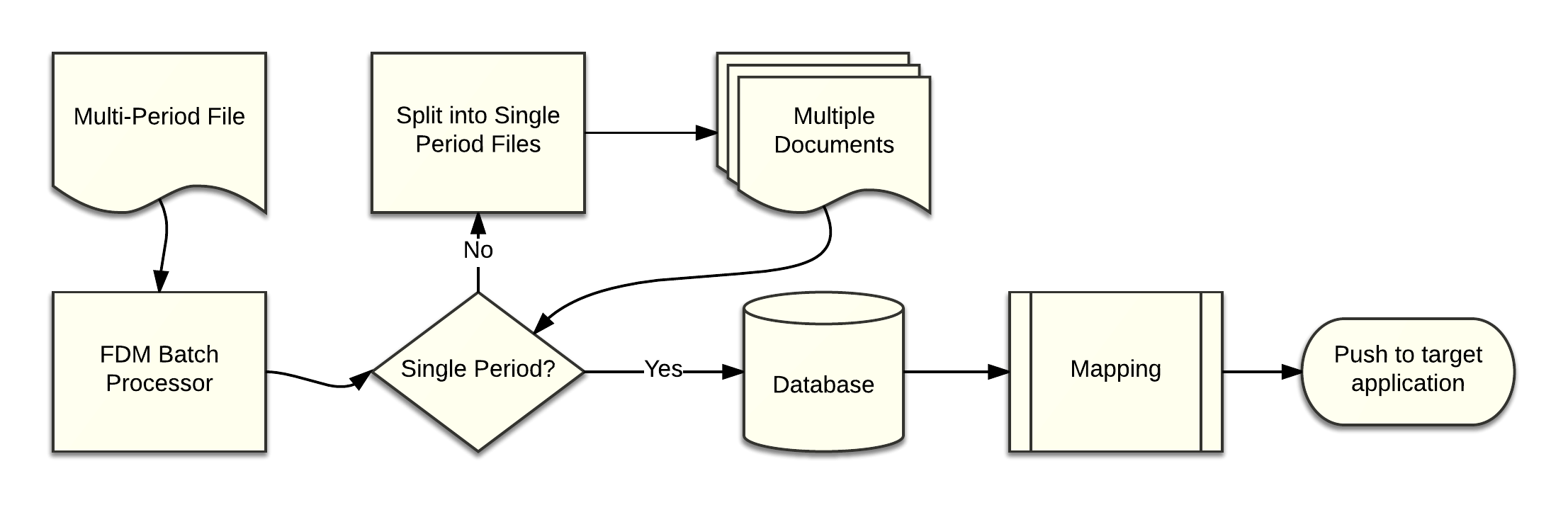
With FDMEE much of the performance penalty has been mitigated, it probably helps that the marshaling of data between Java, .NET and VB have been removed. In FDMEE everything runs through the Java Virtual Machine (JVM). While VB is still an option most customers are now making the switch to Jython which runs natively on the JVM. There is still, however, a problem with multi-period files, the format is quite rigid and requires that import formats dictate the periods that are to be processed. For many customers, this is an issue since we rarely load whole years of data at a time. This leaves users with two options. First, they can create a separate location and import format for each format (Jan-Dec vs Feb-Dec or Jan-Mar). Option two is to split the file into multiple files for processing via the single period. Many clients opt for option two because it eases maintenance of mapping and makes it easier for end users.
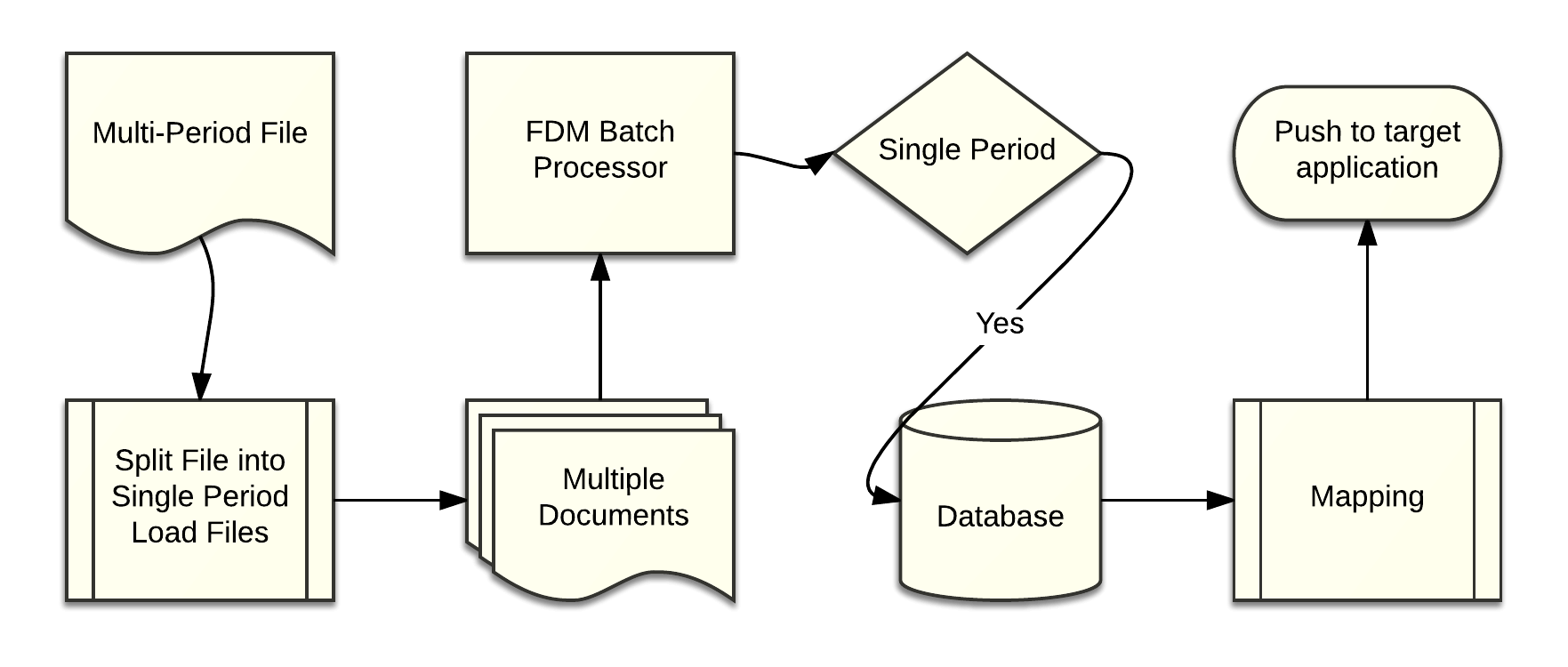
The second option is not without its challenges in that the file must be parsed and files must be named appropriately when using batch processing. When using batch processing files are processed in alphabetical order using a particular naming convention [sort]~[rule name]~[month][year]~RR.txt (ex. a~load rule~Mar2017~RR.txt.) While it's not necessary to use the sort parameter it allows the user to determine the order in which files are processed. Without the sort, files would be processed in alphabetical order (April, August, February, March, etc.)
On a past assignment, the client was using a series of ODI interfaces and variables in a loop to process the files. While effective this was not very portable, reusable and was prone to error. At my insistence, they eventually refactored this process using Jython (this also yielded a small but noticeable performance improvement.) Still, I felt the implementation was not ideal. First, they were making multiple passes through the file in code one for each period. Second, they were not using proper sorting to ensure that files were processed chronologically. Me being me, and having time since we had frozen changes to DRM at the time, I took the opportunity to re-write the process.
First, I set up some variables to set the expected delimiter and file name.
delimiter = "|"
data_load_rule = 'APP_OTLK_Prod'
Next, I wanted to open the file in read mode and determine the dimensions and number of periods. This is done by reading line one for the dimensions and splitting using the delimiter. Reading the periods was a bit trickier since the months were quoted. I used a substitution regular expression to remove the quotes and then stripped the line to remove the trailing newline character.
f = open(data_load_rule + ".txt", 'r+')
dimension = f.readline().split(delimiter) # first line contains dimensions
month = re.sub('"', '', f.readline()).strip().split(delimiter) # second line contains months
File Format:
"Version"|"Organization"|"Scenario"|"Currency"|"Years"|"Measure"|"Period"
"Jan"|"Feb"|"Mar"|"Apr"|"May"|"Jun"|"Jul"|"Aug"|"Sep"|"Oct"|"Nov"|"Dec"
"Final"|"ORG1"|"Actual"|"USD"|"FY17"|"A10000"|10|20|30|40|50|60|70|80|90|100|110|120
Then I used the position of the Years dimension to determine the year in the first line of data, being that it was a 4-digit year and I only wanted the last two characters (16 from 2016) I needed to apply a substring command ([2:0].) Another wrinkle was that the values in the files we received were quoted, I had to use "Years" instead of Years.
line = f.readline().strip()
year = line.split(delimiter)[dimension.index('"Years"')].strip('"')[2:]
At this point, I had the information I needed to determine the number of files I needed to create, so I created a array of file pointers. To allow for easier future use I created a method to perform this task. The method takes in three parameters: the name of the rule, an array of months and the year. Then in the method, I created an array to hold the file pointers and then looped through the months appending file pointers to the array. I used the index of the month in the array to determine the sort. This was done by taking the ordinal value of a and adding the index of the month to it. Then I specified that the files should be opened in write mode before returning the array of file pointers.
def get_files(rule, months, year):
files = []
for month in months:
files.append(open("a%(index)s~%(rule)s~%(month)s20%(year)s~RR.txt" %
{'index': chr(ord('a') + months.index(month)), 'rule': rule,
'month': month, 'year': year}, 'w'))
return files
Next, I created a while loop that ends when a line received blank, making sure to strip newline characters and spaces from beginning and end of lines. Finally, I closed the file pointers to release the memory.
while True:
if line == '':
break
...
line = f.readline().strip()
f.close()
for f in files:
f.close()
Then I needed to process the individual lines of the file into an array of lines that could easily be written to my array of file pointers. To do this I created another method. The first parameter in this method takes an array month data, I generated this by splitting the current line with the delimiter (pipe | in this instance). The next parameter is a positive integer value indicating the number of columns (minus the period columns). The last required parameter is an array of month names. There is also a optional parameter for specifiying the delimiter to be used in the output. Next I created an array to hold the lines I was about to generate in the out variable. Next using the join command I concatenated the dimensions on the line back together to form the dims variable. After I looped through the available months and added items to the out array based on the index of the month being processed. I also checked to make sure that the data value for a particular month was not blank (this ended up making the resulting output files smaller than the previous implementation, which lead to an additional performance gain.)
def create_lines(arr, columns, months, delim='|'):
out = []
dims = delim.join(arr[0:columns])
for i in range(0, len(months)):
if len(arr) > columns + i:
if arr[columns + i]:
out.append("%(dims)s%(delim)s%(month)s%(delim)s%(value)s\n" % \
{'dims': dims, 'month': months[i], 'value': arr[columns + i], 'delim': delim})
else:
out.append("")
return out
I modified the while statement section to output the lines to their respective files. This was done by looping through the lines in the array and using the index respective to the month.
while True:
if line == '':
break
lines = create_lines(line.split(delimiter), len(dimension) - 1, month, delimiter)
for i in range(0, len(lines)):
files[i].write(lines[i])
line = f.readline().strip()
f.close()
for f in files:
f.close()
Below I have included the full script. Please feel free to use all or part of it in your implementation. Cheers.